





Tal como lo decía anteriormente al hablar de la huella digital, muchas compañías como Amazon, Facebook, Google y similares parecen conocer más sobre usted de lo que muchos de sus amigos, familiares y hasta usted mismo sabe, lo cual, es bastante aterrador! Por lo mismo, vale la pena recordar que la huella digital es un activo extremadamente valioso, del cual, se debe tener control para que sea suyo y no de las grandes compañías que se quiere lucrar de su identidad.
Así las cosas, una de las grandes dudas de los antiguos era sí el destino está escrito pero, en la actualidad, ese dilema se ha ido modificando con la existencia de huella digital y, todo parece indicar que, la forma de navegar en internet es lo que, para muchos, está determinando su propia suerte!
¿Ese rastro digital continuo, inevitable y persistente es lo que determina quién es cada persona? ¿Debería ser así?
Muchos están perdiendo oportunidades de trabajo, de acceso a ciertos lugares y hasta a países! Dado que en el proceso de aplicar a ciertas visas es imperativo incluir algunos perfiles de redes sociales. Todo parece estar siendo influenciado por esa navegación voluntaria, involuntaria y, en algunos casos, por esa info que terceros aportan sobre los usuarios (al leer esto, puede que muchos, por cosas de la vida recuerden “The Truman Show”).
Indudablemente hay cierta información en internet que se debería olvidar!
Por lo anterior, el tema del derecho al olvido cada vez parece hacerse más necesario para poder salir de esa memoria colectiva de la red que, la mayoría de las veces juzga a priori, sin un contexto y, sobre todo, sin tener en cuenta la temporalidad.
Es un poco aterrador pensar que toda esa información que se guarda sobre cada usuario no es perfecta, obviamente, puede tener ciertos errores o sesgos debido al proceso de aprendizaje de los algoritmos, en donde, es común que estén sujetos a la interpretación y hasta a los vicios de todos aquellos que hacen las veces de sus entrenadores, teniendo en cuenta que, en ocasiones, el set de datos usado en el proceso puede ser limitado, incompleto, codificado con falta de valores o de forma excluyente hacía algunos grupos éticos, sociales y/o ideológicos. Dando como resultado, normas o reglas sesgadas.
Debido a que los modelos de aprendizaje deben mejorar y perfeccionarse con el tiempo, la higiene de los algoritmos es necesaria periódicamente. Hay que tener en cuenta que es muy diferente entrenar un modelo de Inteligencia Artificial en el laboratorio vs validar dicho aprendizaje en el mundo real, donde los casos de uso se ponen a prueba y, constantemente, hay que hacer correcciones para adaptarlos a la gran diversidad de situaciones del día a día.
El concepto del derecho al olvido que, además no está normalizado en todos los países, genera bastantes dudas, como las siguientes:
- ¿Será posible devolverle los datos a los usuarios?
- ¿Las máquinas pueden olvidar la información personal de algunos sin afectar el proceso de aprendizaje de la Inteligencia Artificial?
Por lo anterior, los investigadores han empezado a validar un nuevo modelo en el cual la data esta dividida en pequeños fragmentos o contenedores, que se entrenan por aparte, de tal forma que, si es necesario borrar o desaprender la información contenida en uno de esos fragmentos, sólo este se vería afectado y tendría que volver a aprender bajo los nuevos parámetros sin afectar todo el algoritmo. Dicho proceso hace más fácil y más rápida la corrección.
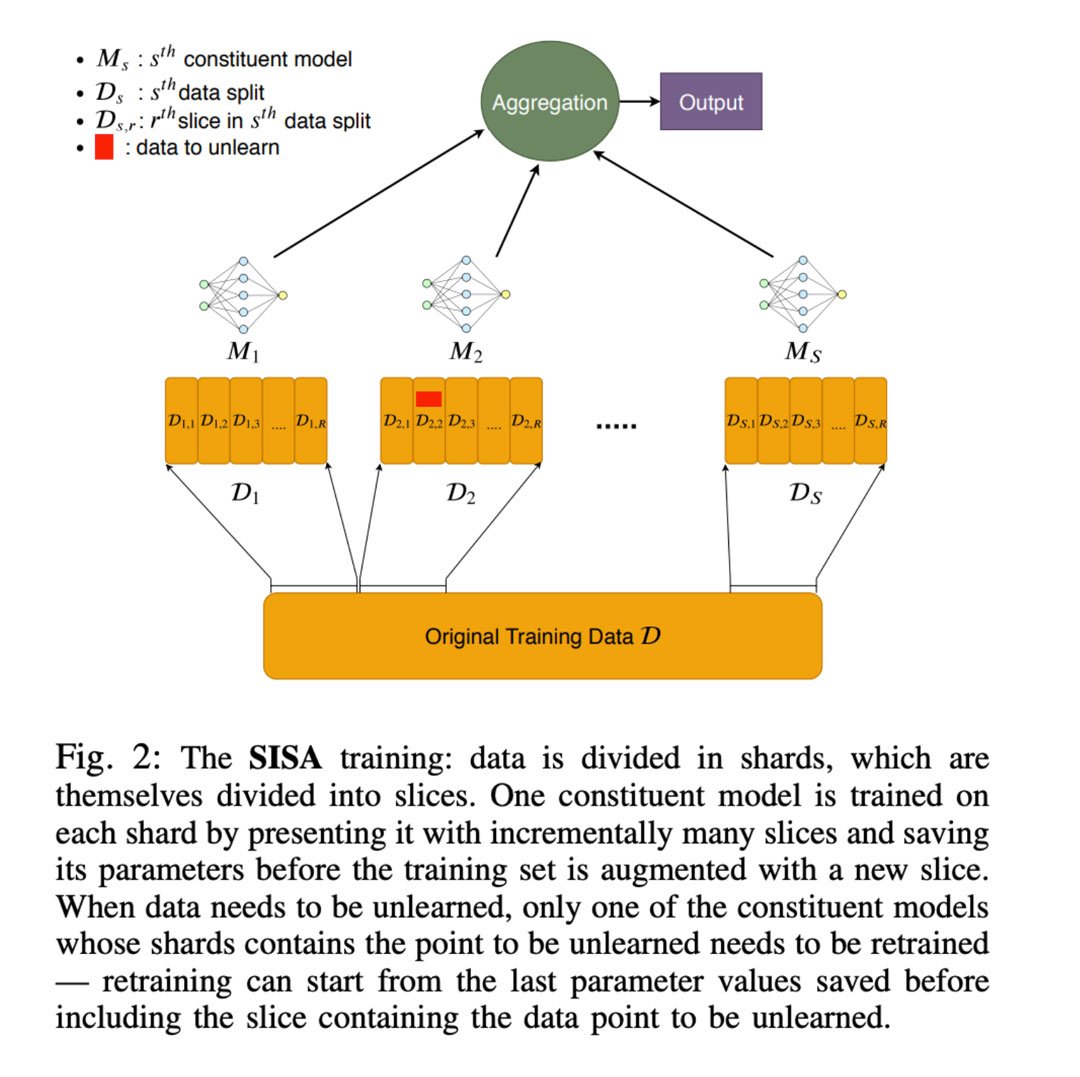
Aunque muy técnico, este nuevo modelo, puede hacer que los encargados del aprendizaje de máquina estructuren la data para cumplir mejor con los llamados legales relacionados con el derecho al olvido sin tener que afectar tan profundamente proyectos monumentales que duran años en el proceso de entrenamiento.
En resumen, todo parece indicar que las máquinas pueden aprender a olvidar y, es muy posible, que los usuarios puedan ejercer su derecho al olvido pero, como era de esperarse, esto está supeditado a la legislación y a la voluntad de las organizaciones creadoras de los algoritmos.



