





En un mundo donde la inteligencia artificial (IA) y el aprendizaje automático (ML) están redefiniendo industrias, los procesadores convencionales como las CPU (Unidades Centrales de Procesamiento) y las GPU (Unidades de Procesamiento Gráfico) ya no son suficientes para satisfacer la creciente demanda de cómputo. Para entrenar modelos de IA como Gemini, GPT-4 u otros similares en tiempos récord, se necesitan chips diseñados específicamente para manejar cálculos masivos de álgebra lineal y operaciones matriciales. Aquí es donde entran en juego las TPU (Tensor Processing Units), una innovación de Google que ha revolucionado la eficiencia en el procesamiento de IA.
¿Qué es una TPU?
Una TPU es un chip diseñado exclusivamente para acelerar el procesamiento de redes neuronales profundas, optimizando tareas clave en inteligencia artificial como:
- Inferencia: La ejecución de modelos entrenados para reconocer imágenes, traducir texto o procesar comandos de voz.
- Entrenamiento: La etapa en la que un modelo de IA “aprende” a partir de millones de datos para mejorar su precisión.
Desde su lanzamiento en 2016, Google han ido mejorando las TPUs en múltiples generaciones, usándolas en servicios como Google Search, Google Photos y Google Assistant, así como en proyectos avanzados de DeepMind como AlphaGo.
Arquitectura: ¿Cómo funciona una TPU?
Las TPUs están diseñadas específicamente para manejar cálculos de tensores, la base del aprendizaje profundo. Su arquitectura es altamente paralela y optimizada para realizar multiplicaciones de matrices y operaciones de acumulación, que son esenciales en las redes neuronales (lo se, suena muy técnico pero, en realidad, lo es!).
Los componentes clave de una TPU
Unidades de Multiplicación de Matrices (MXUs):
Miles de procesadores especializados en operaciones matemáticas simultáneas.
Permiten realizar multiplicaciones y sumas en paralelo, maximizando la velocidad.
Memoria de alto ancho de banda (HBM):
Reduce los cuellos de botella en la transferencia de datos.
Permite que las operaciones en la TPU sean mucho más eficientes que en CPU o GPU.
Precisión adaptativa:
Utilizan formatos de menor precisión (bfloat16 y 8 bits) en lugar de 32/64 bits, lo que permite un rendimiento más rápido sin perder calidad en el entrenamiento de modelos de IA.
Software optimizado:
Las TPUs están integradas con frameworks como TensorFlow y PyTorch, facilitando su uso para desarrolladores de IA.

Hay muchas sigas pero… ¿Cuál es la diferencia?
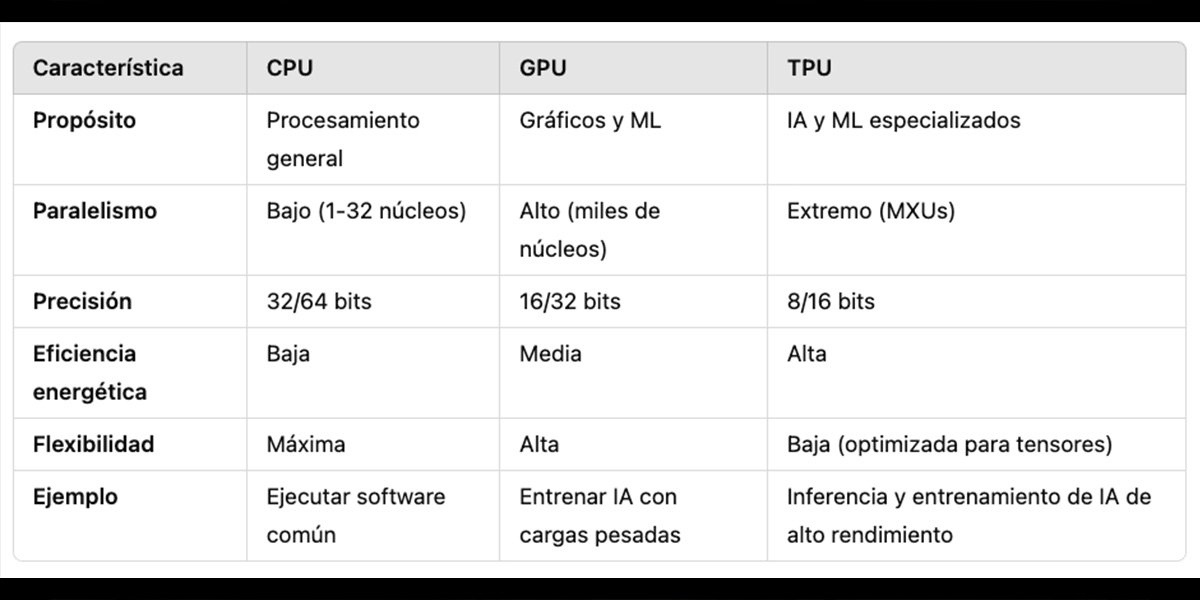
Las CPU (Central Processing Unit) son los “cerebros versátiles” de cualquier dispositivo. Diseñadas para manejar tareas generales (desde navegar en internet hasta ejecutar un sistema operativo), destacan por su flexibilidad y capacidad para gestionar operaciones secuenciales complejas. Sin embargo, su arquitectura (con pocos núcleos potentes) las hace ineficientes para cálculos masivamente paralelos, como los que requiere la inteligencia artificial (IA).
Las GPU (Graphics Processing Unit), originalmente creadas para renderizar gráficos en videojuegos, tienen miles de núcleos pequeños que trabajan en paralelo. Esta capacidad las convirtió en las reinas del machine learning durante años, especialmente para entrenar modelos de deep learning, donde operaciones matriciales (como multiplicar grandes tensores) son clave. No obstante, su diseño aún incluye componentes para tareas gráficas, lo que las hace menos especializadas.
Las TPU (Tensor Processing Unit), creadas por Google en 2016, son chips hechos desde cero para acelerar redes neuronales. A diferencia de las GPU, no pierden tiempo en flexibilidad: su arquitectura se centra en ejecutar operaciones de tensores (como W·X + b) con máxima eficiencia. Integran miles de multiplicadores-acumuladores (MXUs), memoria ultrarrápida y soporte para precisiones bajas (como 16 bits), lo que reduce el consumo energético y acelera tareas específicas de IA, tanto en entrenamiento como en inferencia.
Cuáles son las ventajas y desventajas de las TPUs
Las TPUs son muy importantes en el campo del machine learning y la inteligencia artificial. Diseñadas específicamente para acelerar el procesamiento de redes neuronales, estas unidades ofrecen ventajas significativas frente a las CPU y GPU tradicionales:
- Velocidad: Reducen el tiempo de entrenamiento de modelos de IA de días a horas.
- Costo-efectividad: Consumen menos energía que las GPU, reduciendo costos operativos.
- Escalabilidad: Las TPU Pods, redes de miles de TPUs interconectadas, pueden entrenar modelos de IA a una escala sin precedentes.
Tal como existen ventajas, también hay desventajas, limitaciones o desafíos (llámenlas como quieran) pero, aquí les damos la información:
- Son especializadas, lo que quiere decir que no pueden reemplazar CPU o GPU en tareas generales.
- Están optimizadas para TensorFlow, aunque hay soporte creciente para PyTorch, la compatibilidad es limitada.
- Aunque Google ofrece TPUs en la nube, el acceso a TPU Pods sigue siendo costoso para pequeñas empresas y desarrolladores independientes.
Y… ¿Entonces?
Así las cosas, las TPUs parecen ser una tecnología clave para acelerar la inteligencia artificial pero, vale la pena aclarar que: no son la única opción en el horizonte. Otros competidores están desarrollando tecnologías similares.
Meta apuesta por sus MTIA (Meta Training & Inference Accelerator) para optimizar el entrenamiento y la inferencia en sus plataformas, mientras que Amazon ha lanzado Trainium y Inferentia, chips diseñados para reducir costos en el entrenamiento de modelos en la nube. NVIDIA, por su parte, sigue evolucionando sus GPU H100 y Grace Hopper, combinando IA y computación de alto rendimiento en una sola arquitectura.
El futuro del hardware para IA estará marcado por la especialización: veremos más ASICs (Application-Specific Integrated Circuit) personalizados, chips neuromórficos que imitan el cerebro humano, y avances en computación cuántica que podrían redefinir la forma en que entrenamos modelos de inteligencia artificial. Por lo mismo, las TPUs han abierto el camino, pero la revolución del hardware especializado apenas comienza.



