Reka, una startup de Inteligencia Artificial (IA) con sede en San Francisco fundada por investigadores de DeepMind, Google y Meta, se encuentra presentando un nuevo modelo de lenguaje multimodal denominado “Reka Core”. Vale la pena señalar que el mismo, se anuncia como el “modelo más grande y más capaz” de la empresa y se entrena desde cero usando miles de GPU.
Disponible desde ya a través de API, opciones de implementación local o en el dispositivo, Core viene siendo el tercer miembro de la familia de modelos de lenguaje de Reka y brinda la capacidad de comprender múltiples modalidades, incluidas imágenes, audio y así mismo, video. Cabe destacar que, lo más importante es que, a pesar de haber sido entrenado en menos de 1 año, iguala o incluso supera el rendimiento de los mejores modelos de los principales actores con mucho dinero en el espacio de la Inteligencia Artificial, incluidos OpenAI, Google y Anthropic. ¡Todos los detalles acerca de Reka Core a continuación!
Los datos más destacados que tiene que conocer sobre Reka Core
Yi Tay, quien es científico jefe y cofundador de Reka, escribió en X (anteriormente Twitter) que la empresa usó “miles de H100” para desarrollar Reka Core. Y desarrollar algo desde cero para competir con GPT-4 y Claude 3 Opus de OpenAI es sin duda una hazaña. Advierte que Core continúa mejorando, pero el equipo está impresionado por el desempeño hasta el momento.
Ante esto, es crucial conocer ¿qué aporta Reka Core?
Aunque hasta el momento no se ha revelado el número exacto de parámetros de Reka Core, Yogatama lo describió como un “modelo muy grande” (el último, Reka Flash, tenía 21 mil millones de parámetros) entrenado a partir de múltiples fuentes, incluidos datos disponibles públicamente, datos con licencia y datos sintéticos que abarcan archivos de texto, audio, así como vídeo e imágenes.
Este extenso alcance de capacitación, explicó, permite a Core comprender múltiples modalidades como entrada y ofrecer respuestas en dominios como matemáticas y codificación con un alto nivel de razonamiento. Así mismo, hay soporte para 32 idiomas y una ventana de contexto de 128.000 tokens, lo que permite que el modelo absorba y al mismo tiempo procese grandes cantidades de información diversa de una sola vez. Vale la pena destacar que, esto es apropiado para trabajar en documentos largos. Yogatama indicó que Core es sólo el segundo modelo después de Gemini Ultra de Google que cubre todas las modalidades, desde texto hasta video, y suministra resultados de alta calidad.
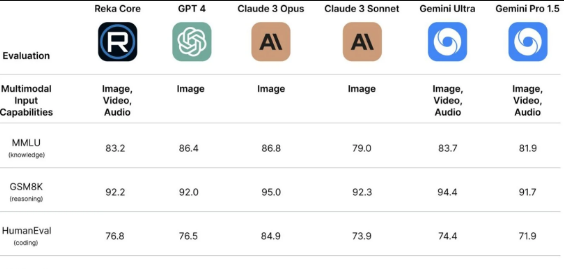
Según se ha podido conocer, en la prueba de percepción de vídeo, Core logró superar a su único competidor, Gemini Ultra, por un margen decente (puntuación de 59,3 frente a 54,3). Mientras tanto, en el punto de referencia MMMU para tareas de imagen, se ubicó justo detrás de GPT-4 (56,8), Claude 3 Opus (59,4), Gemini Ultra (59,4) y Gemini Pro 1.5 (58,5) con una puntuación de 56,3. Ahora bien, xAI de Elon Musk también lanzó recientemente una versión de Grok con capacidad de visión, aunque este modelo aún se encuentra por detrás de sus competidores con una puntuación de 53,6.
Incluso, es crucial acotar que, en otros puntos de referencia, se descubrió que Core se encontraba a la altura de los jugadores líderes de la industria. Por ejemplo, en la prueba MMLU de tareas de conocimiento, obtuvo una puntuación de 83,2, justo detrás de GPT-4, Claude 3 Opus y Gemini Ultra. Mientras tanto, en el punto de referencia GSM8K para razonamiento y HumanEval para codificación, pudo vencer al popular GPT-4 con puntuaciones de 92,2 y 76,8, respectivamente.
Para poder lograr este nivel de desempeño en un período muy corto, Yogatama explicó que la compañía adoptó un enfoque al revés. Esto significa que, en vez de entrenar un modelo y ver a dónde va, comenzaron con un nivel de rendimiento objetivo y posteriormente retrocedieron para descubrir cuál debería ser la mejor y más eficiente forma de lograrlo, cubriendo aspectos como la cantidad de datos que deben almacenarse utilizado para el entrenamiento y la cantidad de GPU requeridas.
Variadas asociaciones en proceso
No se debe pasar por alto señalar que, con un enfoque en todas las modalidades y precios competitivos de $10 por millón de tokens de entrada y la cantidad de $25 por millón de tokens de salida, Reka espera desbloquear casos de uso nuevos y únicos para clientes de diferentes segmentos de la industria, incluidos el comercio electrónico, los juegos, así como la atención médica y la robótica. El GPT-4 Turbo de OpenAI, por contexto, posee el mismo precio para los tokens de entrada pero $30 para la salida.
Reka aún se encuentra en una etapa naciente, sin embargo, hará todo lo posible para asumir el dominio de OpenAI, Anthropic y Google en el dominio de la Inteligencia Artificial. Según se ha podido descubrir, la startup ya ha comenzado a trabajar con socios y organizaciones de la industria para aumentar el alcance de sus modelos. Snowflake, por ejemplo, anunció recientemente la inclusión de Reka Core y Flash en su servicio Cortex para el desarrollo de aplicaciones LLM. Por su parte, Oracle y AI Singapore, que reúne a todas las instituciones de investigación con sede en Singapur y el ecosistema de empresas y empresas emergentes de IA, también se encuentran utilizando los modelos de la empresa.
Sin embargo, hay que destacar que, con todo el trabajo llevado a cabo, Yogatama señaló que la empresa no tiene planes de abrir la tecnología. Expresó que continúa siendo un firme partidario del código abierto, pero que se trata de encontrar el “equilibrio adecuado entre lo que se puede compartir y lo que no” para seguir creciendo como empresa.