





En la era de la inteligencia artificial y el aprendizaje automático, los grandes modelos de lenguaje (LLMs) se han convertido en herramientas esenciales para tareas que van desde la generación de texto hasta la creación de imágenes a través de algoritmos como Stable Diffusion. Por lo mismo, si es un entusiasta de la IA o un profesional que busca potenciar sus proyectos, este anuncio podría resultar interesante, ya que los procesadores AMD Ryzen, combinados con la nueva versión de Amuse 2.2, ofrecen una plataforma poderosa y optimizada para correr estos modelos directamente desde el PC de escritorio.
Gracias a la la inclusión de tecnologías como AMD XDNA Super Resolution, esta combinación promete transformar la forma en que abordamos tareas complejas de IA.
Amuse 2.2 Beta: Una Puerta a Stable Diffusion 3.5
Amuse 2.2 Beta, el software diseñado específicamente para aprovechar al máximo el hardware AMD, ahora incluye soporte completo para la familia de modelos Stable Diffusion 3.5. Con esta actualización, se introduce:
- Stable Diffusion 3.5 Medium y Large: Modelos que permiten generar imágenes de hasta 2 megapíxeles con una fidelidad visual impresionante.
- Calidad mejorada: Un nuevo modo “HQ” (alta calidad) que mejora la adherencia a los prompts y aumenta los detalles en las imágenes generadas.
- Opciones ajustables: Un control deslizante de calidad que ofrece configuraciones para optimizar entre rapidez y fidelidad visual.
Para este momento del tiempo, Amuse 2.2 no solo ofrece una experiencia libre de dependencias, sino que también es relativamente fácil de usar, adaptándose tanto al caso de uso de entusiastas como a profesionales que tengan un buen hardware en su PC de escritorio, sobre todo a nivel de una tarjeta gráfica con mucha VRAM, un chipset eficiente y bastante RAM del sistema.
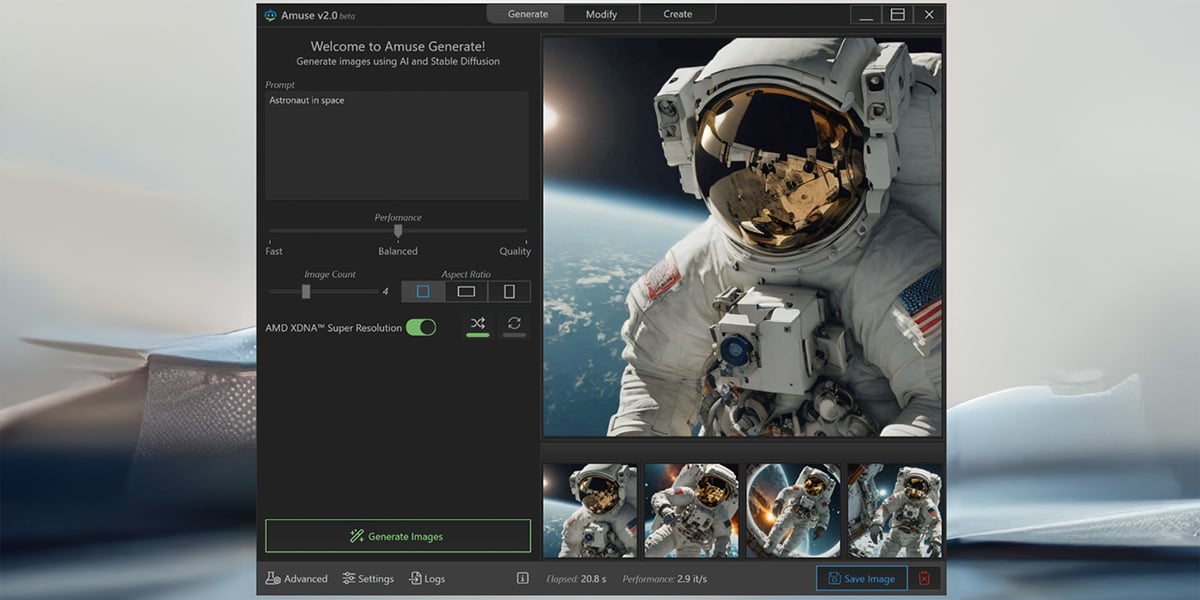
Ventajas de AMD Ryzen y Amuse para Ejecutar LLMs
1. Optimización para Hardware de AMD
Amuse 2.2 ha sido diseñado para funcionar de manera óptima con procesadores AMD Ryzen AI 300 Series y tarjetas gráficas Radeon Serie 7000. Esto significa que es posible esperar un rendimiento buen rendimiento al ejecutar modelos complejos sin comprometer la eficiencia. Ahora bien, no se pueden esperar milagros si la RAM y la VRAM no es suficiente.
2. Soporte para Modelos Grandes
Gracias a la función de “modo mínimo” en Amuse, es posible manejar modelos que no caben completamente en la memoria de video (vRAM) de tu tarjeta gráfica. Este modo carga secuencialmente las diferentes partes del modelo de generación de imágenes, permitiendo que sistemas con 32 GB de RAM puedan ejecutar modelos como Stable Diffusion 3.5 Large.
3. Mejora de la Calidad de Imagen con AMD Ryzen AI
Los usuarios de procesadores AMD Ryzen AI 300 Series disfrutarán de mejoras en la calidad de imagen. Modelos altamente eficientes como Stable Diffusion Lightning ahora están completamente soportados y son el modo “HQ” predeterminado al utilizar Amuse en modo EZ. Esto se traduce en imágenes más detalladas, coherentes y con mayor adherencia a las indicaciones proporcionadas.
Procesamiento en el dispositivo
Amuse 2.2 es un estudio de generación de imágenes por IA libre de dependencias, lo que simplifica enormemente el proceso de instalación y uso. Sólo es necesario descargar el instalador de un clic y, de esta manera, ya está listo para comenzar a crear.
Configuración Recomendada para usar Amuse
Para aprovechar al máximo estas capacidades, aquí tienes una guía rápida:
- Stable Diffusion 3.5 Medium:
- Modo Máximo: AMD Radeon PRO W7900, W7800, AMD Radeon RX 7900 XTX, procesadores AMD Ryzen AI PRO 300 Series (con 64 GB de RAM).
- Modo Mínimo: AMD Radeon RX 7900 XT, procesadores AMD Ryzen AI 300 Series (con 32 GB de RAM).
- Stable Diffusion 3.5 Large y Large Turbo:
- Modo Máximo: AMD Radeon PRO W7900, W7800.
- Modo Mínimo: AMD Radeon RX 7900 XTX con 32 GB de RAM.
Y… ¿entonces?
Sin lugar a dudas, la combinación de AMD Ryzen y Amuse 2.2 abre un mundo de posibilidades para aquellos que desean ejecutar LLMs y modelos de generación de imágenes avanzados directamente desde su PC de escritorio. De esa forma es posible lograr un rendimiento optimizado y la flexibilidad de trabajar con modelos más grandes y complejos que antes estaban limitados a sistemas de alto rendimiento o servidores en la nube.




